Speeding up proteomics with hardware computing solutions
Bogdán IA, Rivers J, Beynon RJ, Coca D. (2008) High-performance hardware implementation of a parallel database search engine for real-time peptide mass fingerprinting. Bioinformatics. 24, 1498-1502. [PUBMED][PDF]
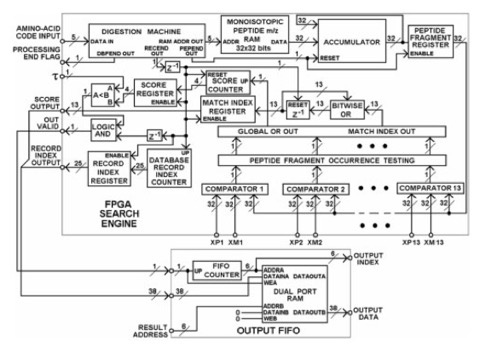
Motivation: Peptide mass fingerprinting (PMF) is a method for protein identification in which a protein is fragmented by a defined cleavage protocol (usually proteolysis with trypsin), and the masses of these products constitute a 'fingerprint' that can be searched against theoretical fingerprints of all known proteins. In the first stage of PMF, the raw mass spectrometric data are processed to generate a peptide mass list. In the second stage this protein fingerprint is used to search a database of known proteins for the best protein match. Although current software solutions can typically deliver a match in a relatively short time, a system that can find a match in real time could change the way in which PMF is deployed and presented. In a paper published earlier we presented a hardware design of a raw mass spectra processor that, when implemented in Field Programmable Gate Array (FPGA) hardware, achieves almost 170-fold speed gain relative to a conventional software implementation running on a dual processor server. In this article we present a complementary hardware realization of a parallel database search engine that, when running on a Xilinx Virtex 2 FPGA at 100 MHz, delivers 1800-fold speed-up compared with an equivalent C software routine, running on a 3.06 GHz Xeon workstation. The inherent scalability of the design means that processing speed can be multiplied by deploying the design on multiple FPGAs. The database search processor and the mass spectra processor, running on a reconfigurable computing platform, provide a complete real-time PMF protein identification solution.